


Welcome to the second blog post of AITU ✋. After our first post, we received a lot of positive feedback and were overwhelmed by the amount of people taking interest in the organisation and joining. Therefore, we are more than happy to say that AITU has now 12 members with diverse educational backgrounds. In our second meeting, we read and discussed the paper MusicLM - Generating Audio from Text released by Google at the end of January this year. MusicLM claims to generate high-quality audio that is consistent over several minutes of playtime in adherence to a minimal text prompt. If you can’t imagine that, feel free to try it yourself. In this post we are summarising our the main takeaways from the paper. Enjoy! 👇

📻 MusicLM summary
🔖 Intro. MusicLM is a sequence-to-sequence model that generates audio conditioned on a text prompt. While text-to-audio models (e.g. Riffusion) already exist, they either generate high-quality music that is inconsistent over longer periods or audio that is coherent but lacking in audio quality. The main challenge for MusicLM was therefore to generate high-quality music that consistently adheres to the text prompt over long periods of time.
😕 Challenges. While there has been immense success of generative models in the fields such as NLP (ChatGPT) or Computer Vision (DALL-E), the text-to-audio field introduces many new challenges.
- Describing audio is hard. Try listening to a couple of the generated audio samples on Google’s Public Research Release without looking at the prompt and come up with your own prompt. You will find that this is an incredibly difficult task to do - especially for non-musicians. Describing audio accurately requires expert knowledge of music features. Ordinary people simply lack vocabulary to describe music.
- Temporal Dimension. A description of an image is restricted to what you see at one point in time. Music adds a temporal dimension, which means that accurate text descriptions also have to capture potential changes in music features over time. The longer the audio, the harder it gets to write a concise matching text.
- Lack of Data. Lastly, the text-to-audio field is heavily understudied in comparison to big AI research areas like computer vision or natural language processing. Researchers are lacking large-scale, high-quality datasets, benchmarks and evaluation metrics. Therefore, the Google Research Team had to get come up with their own evaluation metric as well as dataset.
🧠 Building on previous papers. Striving for consistent, high-quality audio output over long periods of time required a novel approach. The main innovation of the architecture is to model both acoustic tokens and semantic tokens. The MusicLM architecture is based on several previous research papers, puzzling together three large, pre-trained models into a single architecture:

The individual components are:
- MuLan to get embeddings for sound and text tokens that are close to each other if a text matches an audio signal (joint embedding space).
- SoundStream for encoding and decoding audio signals into tokens acoustic token. One second of audio is encoded in 600 acoustic tokens.
- w2v-BERT for extracting semantic tokens from audio signals. It generates 25 semantic tokens per second of audio.
Note, that SoundStream and w2v-BERT have already been combined into an audio-to-audio model called AudioLM by Google. AudioLM is a generative audio-to-audio model, i.e., based on the initial audio input, it produces subsequent audio in the continuation of the input. Therefore, MusicLM can be seen as a natural progression of the AudioLM in a sense that instead of using audio as an input, MusicLM uses text. AudioLM solves two key challenges. First, to keep the model’s output consistent over longer periods, AudioLM translates the continuous audio signal into discrete 🔤 semantic tokens using w2v-BERT that capture things such as local melody, harmony or rhythm. Second, it is equally important to also produce audio with high quality. This is ensured via 🔈 acoustic tokens generated by SoundStream model. These tokens capture details such as recording conditions. For more information, we suggest reading Google’s blog post about AudioLM.
👩🔬 Glueing things together. Let’s talk about how these papers are combined. The figure below taken from the original paper visualises the training procedure.
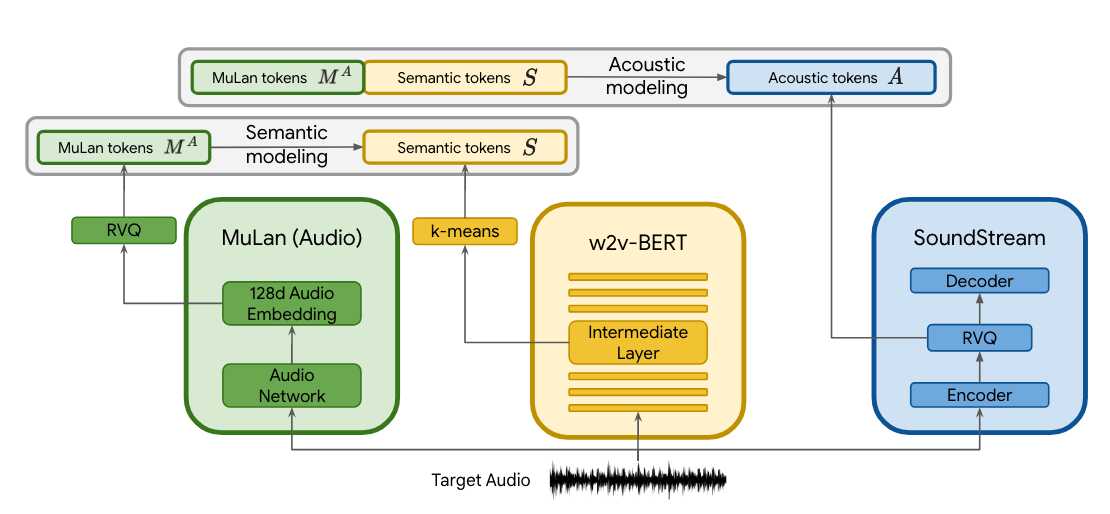
First, notice that during training, only audio data is needed. This is significant since the model does not need text-audio pairs during training. As such, MusicLM was trained on large audio-only datasets. Architecture-wise, MusicLM is a hierarchical sequence-to-sequence model consisting of two layers:
- In the semantic modelling stage a mapping between MuLan audio tokens to the semantic tokens from w2v-BERT is learned using a decoder-transformer architecture (next-semantic-token prediction)
- The acoustic modelling stage takes the output of the semantic modelling stage (thereby being hierarchical) and tries to predict the true audio tokens from SoundStream given the semantic tokens and the MuLan audio tokens in a decoder-transformer architecture (next-acoustic token prediction)
Given these learned layers, new audio can be generated according to the inference procedure depicted below.
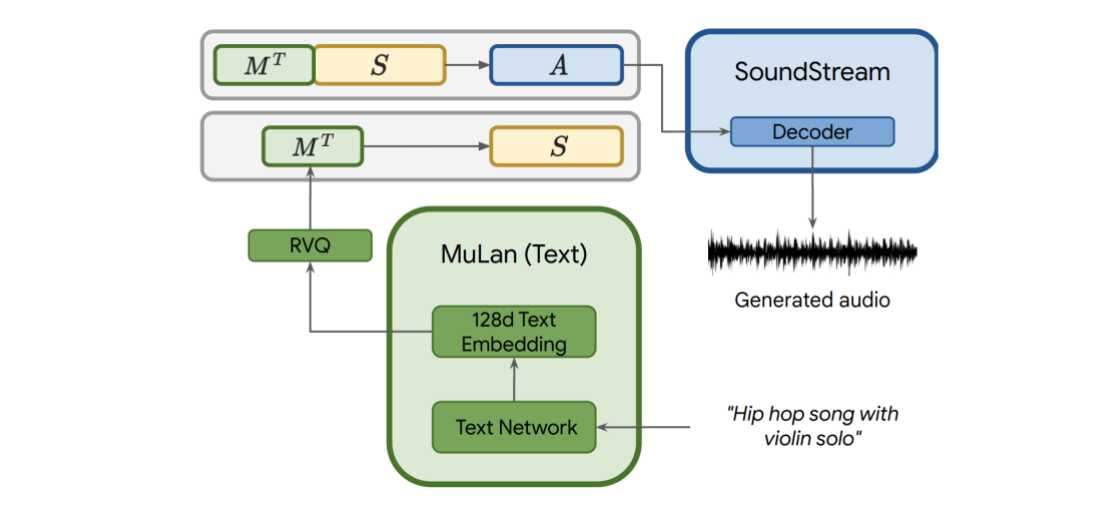
First, the text description is translated into MuLan text tokens. Based on these, semantic tokens are predicted using the trained semantic model. Finally, the concatenation of both MuLan tokens and semantic tokens is used for predicting acoustic tokens. The acoustic tokens are then decoded to actual audio output using SoundStream’s decoder.
🔮 MusicLM key takeaways
🌟 State-of-the-art. MusicLM pushed the boundary of the state-of-the-art in the text-to-audio generation space. The model is not only capable of generating consistent audio over longer periods of time, but the audio is also of higher quality.
🪫 Lack of domain data. Compared to other fields, such as NLP or Computer Vision, there is a lack of large-scale and high-quality text-to-audio data. MusicLM shows a possible workaround by using MuLan joint text and audio embeddings. In addition, as part of the MusicLM paper, a new evaluation text-audio dataset called MusicCaps has been released. Kudos to the Google team for making this open-source and advancing resources in the text-to-audio community.
🧪 Creative evaluation. Evaluating generative AI is difficult in all domains because there is not one single “gold” output. Therefore, the Google research team had to get creative to contrast MusicLM with previous work. They used public models that give scores for the quality of music (FAD score), use classifiers that predict a class label given audio inputs and compare the resulting distributions of class labels between the original audio and generated audio using KL divergence and even used the good-old subjective human voting approach, where they would simply ask experts, which of two audio clips is better output given the text prompt. Overall, it seems that there is work to be done and that the field lacks common benchmarks and metrics.
📣 Stay in touch
That’s is for this week, hope you enjoyed reading this post. 😊 To stay updated about our activities, make sure you give us a follow on the LinkedIn and Subscribe to our Newsletter. Any questions or ideas for talks, collaboration etc.? Drop us a message at hello@aitu.group.