



Hello and welcome to our weekly blog post! 🙌 Before the easter break, we read another exciting recently published paper. Language Is Not All You Need: Aligning Perception with Language Models introduces Kosmos-1, a multimodal large language model (MLLM), that is capable of understanding both image and natural language (or a mix of them). It is an exciting new development in the world of large language models (LLMs) that some believe to be a possible path towards generally intelligent systems (AGI) 🧠.
We are excited to share the core ideas behind the architecture, as well as our thoughts on the paper. Let’s get started! 🚀
👁️👂👃✋👅 Multi-Modality
Before jumping into the paper, let’s try to unwrap the concept of multi-modality to understand why it is a desirable goal to implement in AI systems 🧐.
Multi-modality refers to the fact that most living organism perceive their surrounding world through multiple senses. For example, we humans are able to perceive the world through our five senses (sight, hearing, smell, taste, touch) and combine them to form a multi-modal perception of the world. This is a fundamental ability that enables us to understand the world around us. 🌎
Thus far, most of the AI systems that we have developed are narrow AI systems that are only capable of understanding a single modality. For example, a computer vision system is only capable of understanding images, a speech recognition system is only capable of understanding audio, and a language model is only capable of understanding text. 📝
Given this inherent architectural limitation, AI researchers have been trying to develop systems that are capable of understanding multiple modalities similar to us humans. They hope that this enhancement might be a key step towards developing systems with intelligence levels similar or beyond us humans on a wide-variety of tasks, referred to as AGI. 🧠
🏗 Kosmos-1
Multi-Modality seems like a desirable goal. Even if it does not directly lead to AGI, one can think of many applications where it would be beneficial to have a system that is capable of understanding multiple modalities (ChatGPT with images, etc.).
The key problem for multi-modal models is that the digital representation of different modalities are fundamentally different. For example, an image is a 2D array of pixels where each pixel is represented by a 3D vector of RGB values. On the other hand, a text is a sequence of words where each word is represented by a vector of word embeddings. Thus, it is not obvious how we can build a single model that is capable of understanding all these modalities at the same time.
How do we puzzle everything together? 🧩 The research team at Microsoft builds on previous in-house research (paper) and proposes to use language models as a general-purpose-interface that decodes encoded representations of different modalities.
Architecturally, for each modality, a foundation perception module is trained to encode the modality into a fixed-length vector representation (encoder). This vector is then fed into the general-purpose-interface (Figure 1) to decode the vector into a sequence of words (decoder), which is the final output.
The architecture is very modular and most of the building blocks already exist. For most modalities, we already have foundation models that are capable of encoding the modality into a vector representation. For example, we have BERT for text, ViT for images, and Wav2Vec2 for audio, which were all trained in a self-supervised manner on large, unlabelled corpora of data.
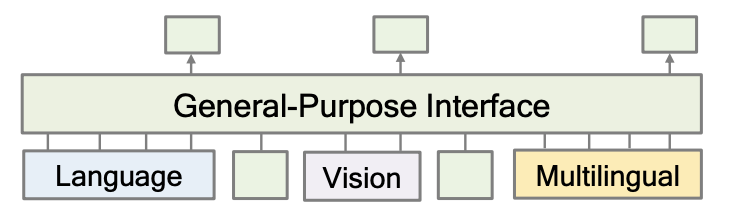
Figure 1: A general-purpose-interface that decodes encoded representations of different modalities.
Let’s look at some concrete prompts that Kosmos-1 with its two perception
modules can answer (Figure 2). Before feeding a prompt into the model, the
prompt is pre-processed to denote, which modality is used. Text prompt are
surrounded by the special tokens <s> and <\s>, and image prompts are
surrounded by the special tokens <image> and <\image>. Next, the data
encapsulated by a set of special tokens is fed into the respective perception
module. The vector representations of the text, images and special tokens are
then concatenated and fed into a single transformer decoder, which produces text
in an autoregressive manner.

Figure 2: Some examples of prompts to Kosmos-1. The model can handle pure text and text-image prompts.
The Microsoft team was able to produce some pretty impressive results (Figure 3) and previewed potential applications of multi-modal models. The fact that there is a market for these kind of models it underlined by the long-awaited release of GPT-4 by OpenAI, which also features a multimodal architecture (although the multi-modal model is not yet available to the public).
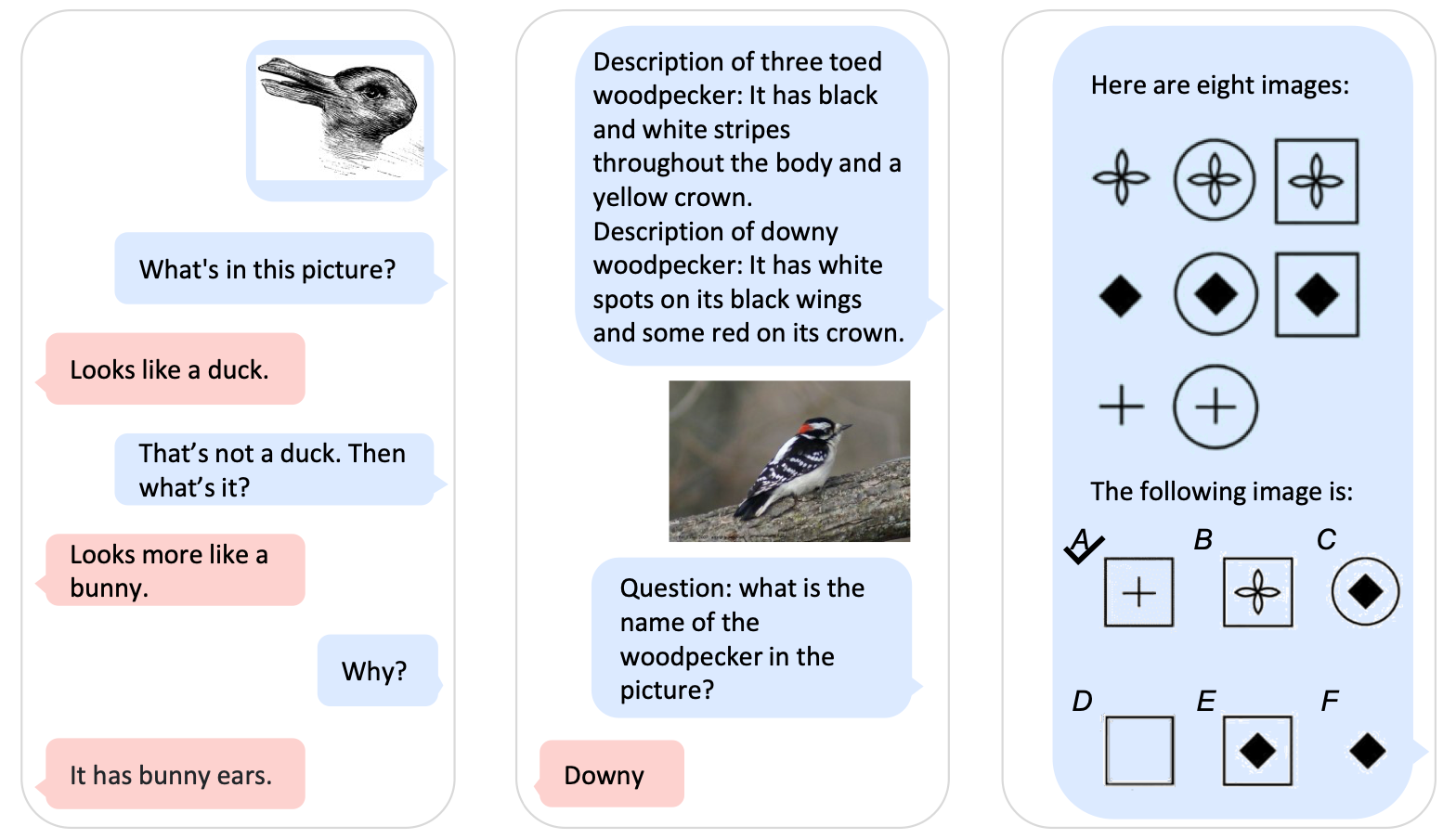
Figure 3: Some examples of outputs from Kosmos-1. The model can handle pure text and text-image prompts.
📊 Evaluation
Kosmos-1 was evaluated using a lot of different techniques. Too many for us to cover in this blog post. However, one particularly striking one was the Raven’s Progressive Matrices 🐦 test.
It is a well-known tool in the field of neuroscience to measure fluid reasoning abilities of humans. The test consists of a series of 3x3 matrices with one missing element. The task is to identify the missing element from a set of six candidates (Figure 4).
Fluid Reasoning describes the capacity to think logically and solve problems in novel situations, independent of acquired knowledge - Catell, 1987
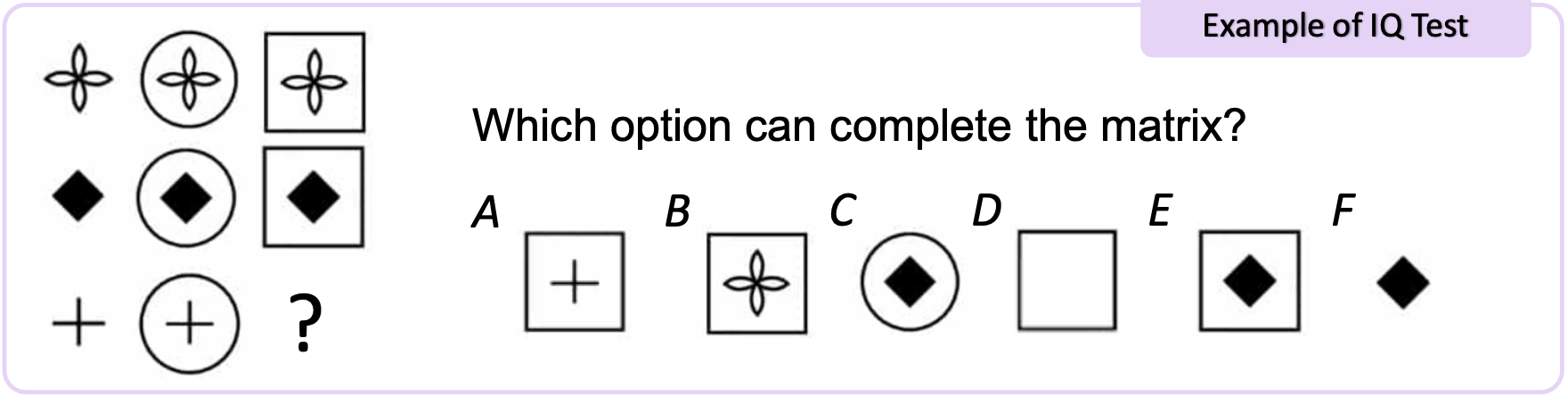
Figure 4: An example of a Raven’s Progressive Matrices test.
Looking at the results (Figure 5), we can see that the model is able to solve the test with a slight improvement over a random choice. This is a very exciting result, because it shows that the model is able to acquire some common sense knowledge. For example, the model is able to reason about symmetry and transitivity. It is incredible to see how we have come to a point where we benchmark models on a test that is used to measure IQ’s of humans 🤯.

Figure 5: Results of Kosmos-1 on subset of Raven’s Progressive Matrices test.
🔮 Key Takeaways
👀 Multi-Modality. The ability to understand multiple modalities that are combined into a single world representation is engrained in human cognition. Taking inspiration from the human brain, multi-modal models seem like a promising direction to explore.
🧠 AGI (?) Whether, when or how that direction will lead to AGI, is nothing more than a guessing game at this point. However, it is an interesting and thought-provoking exercise. Hypothesising about a future with generally intelligent systems is so complex, that we cannot start thinking about its implications early enough. Reading papers like this one is a great way to start.
🚧 Architecture. Architecturally, the proposed model is modular and relies on the fact that we already have a lot of different perception models that encode different modalities into a high-level vector representation. Concatenating those is presumed to be enough to build a multi-modal model.
📈 Future Work. It was evident when reading the paper that there is still a lot of room for improvement in this domain. Kosmos-1 is lacking truly large scale, high-quality cross-modal data sets, alignment techniques and more. GPT-4 by OpenAI seems more advanced judging their initial announcement of the model, but much of it is speculative, as their model is not yet public and OpenAI has not shared details about the model’s training procedure.
📣 Stay in touch
That’s it for this week. We hope you enjoyed reading this post. 😊 To stay updated about our activities, make sure you give us a follow on LinkedIn. Any questions or ideas for talks, collaboration, etc.? Drop us a message at hello@aitu.group.